Heap
Heap adalah struktur data yang berbentuk pohon yang merupakan jenis dari binary tree. Heap juga mempunyai karakter dimana masing-masing node mempunyai maksimum dua children sebagaimana terdapat di dalam binary tree. Heap juga merupakan complete binary tree yang memenuhi sifat - sifat heap.
Heap Property
- Min Heap
- dimana setiap key dalam node bernilai lebih kecil dari children-nya
- Max Heap
- dimana setiap key dalam node bernilai lebih besar dari children-nya
- dimana setiap key dalam node bernilai lebih kecil dari children-nya
- dimana setiap key dalam node bernilai lebih besar dari children-nya
Min Heap
- Setiap key dalam node bernilai lebih kecil dari key children-nya.
- Key yang bernilai paling kecil berada di root.
- Key yang bernilai paling besar berada di salah satu dari node leaves.
- Heap bisa diimplementasikan menggunakan linked list, namun lebih mudah diimplementasikan dengan menggunakan array

Applications of Heaps
- Heap Sort
- Selection Algorithm
- Graph Algorithm
Selection Algorithm
- menemukan key minimum atau maksimum, mencari median, dan menentukan elemen k terbesar, dan lainnya
- algoritma Djikstra, dimana digunakan untuk menemukan path terpendek dalam suatu graf
- algoritma Prim, dimana digunakan untuk mencari minimum spanning tree (untuk mendapatkan cost terkecil)
Heap Sort
Heap sort adalah sebuah metode sorting (pengurutan) angka pada sebuah array dengan cara yang menyerupai binary tree, yaitu dengan cara memvisualisasikan array di dalam binary tree dimana index-nya akan diurutkan selanjutnya. Pada heap sort terdapat tiga bagian yaitu, node, edge, dan leaf dimana node itu adalah setiap index yang ada di dalam array, edge adalah garis yang menghubungkan dua node, dan leaf adalah setiap node yang tidak memiliki child node (node turunan). Selain itu juga terdapat root yang merupakan node awal dalam sebuah heap.




Karena pada heap tree jumlah node atau elemen ada 10 (dimana array ada 9), maka jumlah elemen dibagi 2 (10/2 = 5 dan 9/2 = 4) maka yang menjadi variabel i adalah 5 (untuk heap tree) atau 4 (untuk array) maka ilustrasinya adalah sebagai berikut :

Karena node parent sudah bernilai lebih besar dari child nodenya (16 > 7), maka pengecekkan berlanjut ke index berikutnya.

Disini, ternyata nilai yang dimiliki oleh index 4 bernilai lebih kecil dari kedua childrennya. Dalam kasus ini, akan ada penukaran elemen dengan perubahan sebagai berikut:

Selanjutnya adalah node 3 (index 3)




Pada metode heap sort, jenis heap tree yang digunakan adalah Max-Heap. Untuk memvisualisasikan sebuah array menjadi sebuah heap tree, maka kita harus mencari node root terlebih dahulu, dimana node root adalah node pertama di dalam sebuah tree dengan index 0. Setelah node root ditemukan, maka kita harus mencari child node dari node root tersebut. Child node sendiri terbagi menjadi dua yaitu, left child dan right child. Untuk mencari child node, kita dapat menggunakan rumus berikut :
- Left Child : 2i
- Right Child : 2i + 1
- Parent : i/2
dimana i adalah index node yang diketahui. Jadi, apabila kita ingin mencari left child dari node di posisi pertama, maka left child-nya berada di i*2 = 1*2 = posisi kedua (index = 1, karena index dimulai dari 0), sedangkan untuk mencari right child node posisi keempat, maka right chid-nya berada di (i*2) + 1 = (4*2) + 1 = 8+1 = posisi 9 (index = 8). Untuk mencari parent dari node di posisi kelima, maka parent berada di i/2 = 5/2 = 2.5 = posisi kedua (pembulatan ke bawah, index = 1)
Disini kita akan memisalkan sebuah array A = 4, 1, 3, 2, 16, 9, 10, 14, 8, 7. Untuk memvisualisasikan array tersebut di dalam heap tree, kita hanya perlu menyusunnya susai dengan index masing-masing elemen.
Disini kita harus menyusun heap tree dengan function yang mengkaitkan satu elemen dengan elemen lainnya sebagai berikut :
Dengan penyusunan seperti di atas, maka dapat digambarkan heap tree sebagai berikut :
Akan tetapi pada metode heap sort, dibutuhkan heap tree dalam kondisi max-heap. Disini kita dapat melihat bahwa tidak semua parent node bernilai lebih besar dari child node (ini adalah sifat max-heap), maka kita perlu menyusun heap tree dalam kondisi max-heap. Maka kita membutuhkan dua metode heap sort, yaitu Build-Max-Heap dan Max-Heapify
Berikut ini adalah ilustrasi dari penggunaan metode HeapSort, Build-Max-Heap, dan Max-Heapify dalam sebuah heap tree :
HeapSort(A)
- Deklarasi array A
- Deklarasi elemen
- Input elemen array A
- Input nilai-nilai elemen array A
- Build-Max-Heap
- for (i = elemen-1 ; i >0)
- Tukar A[i] dengan A[0]
- Elemen-1
- Max-Heapify(A, 1)
- End for
Dapat dilihat bahwa fungsi HeapSort akan memanggil dua fungsi yaitu Build-Max-Heap dan Max-Heapify, algoritma dari Build-Max-Heap adalah :
Build-Max-Heap(A)
- for(i = (elemen-1)/2 ; i>=0)
- Max-Heapify(A,i)
- End for
Pada metode Build-Max-Heap terdapat for looping yang membagi dua jumlah elemen, disini elemen-1 karena pada array index awal adalah 0, sedangkan pada heap tree adalah 1, lalu elemen dibagi menjadi 2 dan selama i>= 0 maka for looping akan terus berjalan dan berikut ini adalah metode Max-Heapify :
Max-Heapify(A,i)
Max-Heapify(A,i)
- Deklarasi left = (i+1)*2 - 1
- Deklarasi right = (i+1)*2
- Deklarasi largest
- if(left < elemen dan A[left] > A[i])
- largest = left
- end if
- else
- largest = i
- end else
- if(right < elemen dan A[right] > A[i])
- largest = right
- end if
- if(largest != i)
- Tukar A[i] dengan A[largest]
- Max-Heapify(A,i)
- end if
Misalkan ini adalah heap tree awal :
Karena node parent sudah bernilai lebih besar dari child nodenya (16 > 7), maka pengecekkan berlanjut ke index berikutnya.
Disini, ternyata nilai yang dimiliki oleh index 4 bernilai lebih kecil dari kedua childrennya. Dalam kasus ini, akan ada penukaran elemen dengan perubahan sebagai berikut:
Selanjutnya adalah node 3 (index 3)
Disini node 3 bernilai lebih kecil dibandingkan kedua childrennya (9 dan 10). Maka akan terjadi penukaran dan perubahan sebagai berikut:
Selanjutnya kita akan mengamatii node 1 (index 2)
Disini ternyata node 1 bernilai lebih kecil dari kedua childrennya (14 dan 16), maka akan terjadi penukaran dengan children terbesarnya (hal ini karena setiap parent harus mempunyai nilai yang lebih besar dari childrennya) dan akan terlihat seperti gambar berikut :

Selanjutnya, kita beralih ke index 1 (root):

Disini kita melihat bahwa node 4 lebih kecil kedua childrennya (16 dan 10). Maka akan terjadi penukaran antara node 4 dengan node children max (16) seperti dibawah ini:

Disini kita akan mengecek kembali ke index 2 karena adanya perubahan yang ada dimana node 4 masih bernilai lebih kecil dari kedua childrennya (14 dan 7) dan akan mengalami perubahan sebagai berikut :

Dalam kasus ini, kita tidak mengecek index 3 karena parent (10) sudah bernilai lebih besar dari kedua childrennya (9 dan 3). Kita akan mengecek ke index 4, dimana node parentnya (4) masih mengalami violation karena bernilai lebih kecil dari childrennya (8). Disini akan terjadi penukaran dengan hasil seperti berikut :

Selanjutnya, kita beralih ke index 1 (root):
Disini kita melihat bahwa node 4 lebih kecil kedua childrennya (16 dan 10). Maka akan terjadi penukaran antara node 4 dengan node children max (16) seperti dibawah ini:
Disini kita akan mengecek kembali ke index 2 karena adanya perubahan yang ada dimana node 4 masih bernilai lebih kecil dari kedua childrennya (14 dan 7) dan akan mengalami perubahan sebagai berikut :
Dalam kasus ini, kita tidak mengecek index 3 karena parent (10) sudah bernilai lebih besar dari kedua childrennya (9 dan 3). Kita akan mengecek ke index 4, dimana node parentnya (4) masih mengalami violation karena bernilai lebih kecil dari childrennya (8). Disini akan terjadi penukaran dengan hasil seperti berikut :
Sampai langkah ini, proses Build-Max-Heap telah selesai karena masing-masing parent node sudah bernilai lebih besar dari child node dengan heap tree akhir sebagai berikut :

Setelah menggunakan metode Build-Max-Heap telah selesai, baru kita dapat menggunakan metode HeapSort untuk mengurutkan nilai pada array A. Setelah proses Build-Max-Heap, nilai pada index terakhir i akan ditukar dengan node 1 atau root selaam i > 0. Nilai 16 akan ditukar dengan nilai 1 dan jumlah elemen akan dikurangi 1. Namun, hal ini akan menyebabkan violation karena tidak memenuhi kondisi Max-Heap maka algoritma Max-Heapify akan dijalankan dengan ilustrasi sebagai berikut :

Sampai pada tahap ini, nilai tertinggi sudah berada di index yang benar (index terakhir 10 pada heap tree dan 9 di array). Langkah selanjutnya adalah mengulang langkah yang sama dengan for looping selama i > 0. Berikut ini adalah ilustrasi lengkapnya :



Maka, setelah algoritma HeapSort dilakukan, nilai-nilai pada array akan terurut dari nilai terkecil sampai nilai terbesar. A = 1, 2, 3, 4, 7, 8, 9, 10, 14, 16. Dan berikut adalah flowchat untuk algoritma HeapSort

Heap for Priority Queue
- Heap adalah implementasi dari priority queue sebuah data structure
- find-min : menemukan elemen terkecil dalam heap
- insert : memasukkan elemen baru ke dalam heap
- delete-min : menghapus elemen terkecil dari dalam heap
Array Implementation
- Heap biasanya sudah diimplementasikan dalam array
- Elemen secara berurutan disimpan dari index 1 sampai N, dari atas ke bawah, dan dari node kiri ke node kanan dalam sebuah tree
- Root disimpan dalam index 1 (kita misalkan index 0 kosong untuk tujuan keamanan)
- Setiap node memiliki hubungan dengan parent, left child, dan right child untuk mempermudah pengecekkan
- Misalkan node yang sedang kita cek ber-index x.
- Parent(x) = x/2
- Left-child(x) = 2*x
- Right-child(x) = 2*x + 1
Find-Min in Min-Heap
- Find-Min dalam Min-Heap cukup mudah
- Min-Heap pasti terletak di root, maka
- int findmin() {return data[1];}
Insertion in Min-Heap
- Ketika kita ingin memasukkan elemen baru dalam heap, kita harus tetap memperhatikan sifat-sifat heap
- Memasukkan setiap elemen baru di akhir heap (setelah index dari elemen terakhir)
- Upheap elemen baru (Menyesuaikan dengan sifat-sifat heap)
Upheap in Min-Heap
- Membandingkan current node dengan parent node. Jika current node bernilai lebih kecil dari parent node maka kita harus melakukan tukar value dan melanjutkan UpHeap
- Proses dihentikan jika parent node lebih kecil dari current node atau current node merupakan root (tidak punya parent)
Example of Insertion in Min-Heap
insert new node (20)

insert new node (5)


Deletion in Min-Heap
- Deletion dilakukan terhadap elemen terkecil yang terletak di root
- Mengganti posisi root dengan elemen terakhir dalam heap
- Mengurangi jumlah elemen dalam heap
- DownHeap root (Menyesuaikan dengan sifat-sifat heap)
DownHeap in Min-Heap
- Membandingkan current node (dimulai dari root) dengan left child dan right child. Apabila current node bernilai lebih besar dari child, maka lakukanlah penukaran value dan lanjutkan proses pada (child) node
- Proses dihentikan apabila current node sudah bernilai lebih kecil dari kedua children-nya atau current node merupakan leaf (tidak punya child)
Example Deletion in Min-Heap
Delete node(7)

Ganti root dengan elemen terakhir, node(28)
Cari posisi node (28) sesuai dengan sifat Min-Heap

Heap Complexity
- find-min : O(1)
- insert : O(log(n))
- delete-min : O(log(n))
Max-Heap
- Setiap elemen node bernilai lebih besar dari child node
- Elemen terbesar terletak di root
- Max-Heap memiliki konsep yang sama dengan min-heap dimana bisa digunakan untuk membuat priotity queue dengan mencari elemen yang terbesar, dimana min-heap mencari elemen terkecil
Min-Max Heap
- Kondisi heap secara bergantian menunjukkan minimum dan maximum dari setiap level.
- Setiap elemen di level ganjil bernilai lebih kecil dari children di level ganjil
- Setiap elemen di level genap bernilai lebih besar dari children di level genap
- Tujuan dari min-max heap adalah mempermudah kita dalam menemukan kedua elemen, baik elemen terbesar maupun elemen terkecil dalam heap di waktu yang bersamaan.
Di dalam Min-Max Heap :
- Elemen terkecil terletak di root
- Elemen terbesar terletak di salah satu child dari root (left child atau right child)
- Elemen terbesar bisa terletak di root jika hanya ada satu elemen di dalam heap
findmin() {return data[1]; }
findmax() {return max(data[2], data[3]; }
Insertion in Min-Max Heap
- Elemen baru dimasukkan di akhir heap (setelah index dari elemen terakhir)
- Upheap elemen baru
- Upheap di dalam max-min heap berbeda dengan Upheap dalam min-heap ataupun max-heap
Upheap in Min-Max Heap
- Jika new node terletak di min-level
- jika parent new node bernilai lebih kecil dari new node, maka terjadi penukaran nilai dan upheapmax dari parent new node
- selain itu, upheapmin dari new node
- Jika new node terletak di max-level
- Jika parent new node bernilai lebih besar dari new node, maka terjadi penukaran nilai dan upheapmin dari parent new niode
- selain itu, upheapmax dari new node
Upheapmin and Upheapmax in Max-Min Heap
- Upheapmin
- Membandingkan current node dengan grand-parent node. Apabila current node bernilai lebih kecil dari parent node, maka tukar dan rekursif upheapmin dengan grand-parent node.
- Upheapmax
- Membandingkan current node dengan grand-parent node. Apabila current node bernilai lebih kecil dari parent node, maka tukar dan rekursif upheapmin dengan grand-parent node.

- Upheapmin : 50 lebih besar dari parent node (28), maka upheapmax.
- Upheapmax : 50 lebih besar dari grand-parent node (35), maka tukar nilai keduanya.

- Upheapmax : karena node 50 tidak memiliki grand-parent, maka proses selesai
Insert 5

Upheapmin : 5 bernilai lebih kecil dari parent (14), maka tukar nilai dan rekursif upheapmin

Upheapmin : 5 bernilai lebih kecil dari grand-parent (8), maka tukar nilai dan rekursif upheapmin

Upheapmin : karena 5 tidak memiliki grand-parent, maka proses dihentikan
Deletion in Min-Max Heap
- Deletion of the smallest element
- Ganti root dengan elemen terakhir dalam heap
- Kurangi jumlah elemen dalam heap
- Downheapmin dari root
- Deletion of the largest element
- Ganti left child atau right child dari root (elemen terbesar) dengan elemen terakhir dalam heap
- Kurangi jumlah elemen dalam heap
- Downheapmax dari root
Downheapmin/max in Max-Min Heap
- Downheapmin
- Misalkan m adalah elemen terkecil dari current node children dan grandchildren
- Jika m adalah grandchildren dari current node maka
- Jika m bernilai lebih kecil
- Tukar nilai
- Jika m lebih besar dari parent maka tukar nilai
- Rekursif downheapmin dari m
- Jika m adalah children dari current node
- Jika m lebih kecil dari current node
- Tukar nilai
- Downheapmax memiliki konsep yang sama dengan operator relasi yang dibalik
Min-Max Heap Delete Max

- Ganti nilai maksimum (50) dengan last node (14)

- Downheapmax : cari elemen terbesar dari children dan grandchildren. Setelah itu, tukar nilai keduanya

- Karena parent dari 14 bernilai lebih besar, maka tukar nilai keduanya, dan rekursif downheapmax
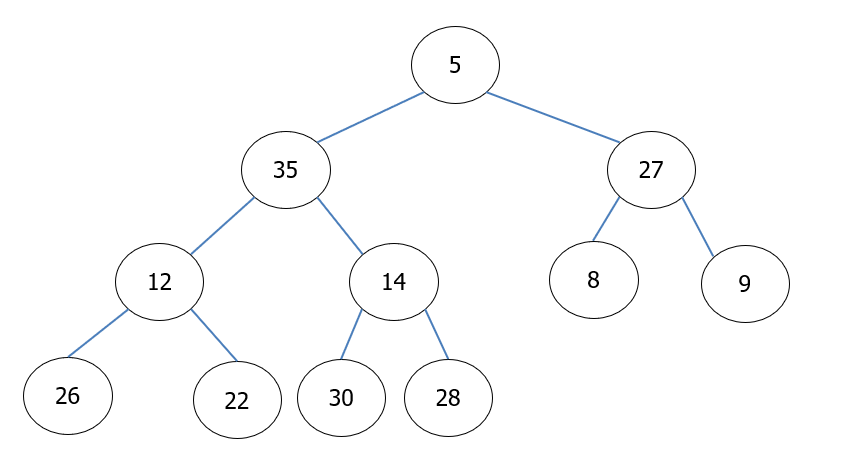
- Karena 28 tidak memiliki children ataupun grandchildren, maka proses selesai
Tries
- adalah suatu tree yang tersusun dalam data structure dengan menggunakan array (string)
- tries dapat menemukan satu kata di dalam kamus hanya dengan prefix dari sebuah kata
Property
- tries adalah tree dimana setiap vertex menggambarkan satu kata atau prefix
- root disimbolkan sebagai karakter kosong ('')
- vertex yang memiliki k sisi dari root memiliki prefix dengan panjang k
- jika a dan b adalah vertices dari sebuah tries dan kita mengasumsikan bahwa a adalah direct parent dari b, maka b adalah prefix asosiasi dari a
Example

Misalkan terdapat tries yang memuat kata-kata berikut :
- Algo
- Api
- Bom
- Bos
- Bosan
- Bor
kita bisa mengimplementasikan tries dengan structure berikut :
struct trie { char chr; int word; struct trie* edge[128];} *root = 0;•root = (struct trie*)malloc(sizeof(struct trie));root->chr = ‘’;root->word = 0;
chr adalah karakter yang disimpan di dalam node
word akan bernilai 1 jika ada kata yang berada di akhir node, selain itu nilai word 0
Insertion in Tries
Untuk memasukkan word ke dalam tries, kita dapat menggunakan code berikut :
main function
char
s[100];
insert(root,
s);
void
insert(struct trie *curr, char *p) {
if ( curr->edge[*p] == 0 )
curr->edge[*p] = newnode(*p);
if ( *p == 0 ) curr->word = 1;
else insert(curr->edge[*p],p+1);
else insert(curr->edge[*p],p+1);
}
newnode() function
struct
trie* newnode(char x) {
struct trie* node =
(struct trie*)malloc(sizeof(struct trie));
node->chr
= x;
node->word = 0;
for (i = 0; i < 128; i++ )
node->edge[i] = 0;
return node;
}Finding in Tries using Prefix
misalkan kita ingin menemukan semua string yang mungkin dengan prefix yang ada :
pertama, kita harus meletakkan lokasi karakter terakhir (s/prefix) di dalam tries :
char
s[100] = {“...”}; // global
•
int i, n, okay;
struct
trie *curr;
n = strlen(s);
okay
= 1;
curr
= root;
for
( i = 0; i < n && okay == 1; i++ )
if ( curr->edge[s[i]] == 0 ) okay = 0;
else curr = curr->edge[s[i]];
if
( okay ) find(curr,n);
dan find function (akan mencetak semua kemungkinan strings yang memiliki prefix)
void
find(struct trie *curr, int x) {
if ( curr->word == 1 ) {
s[x] = 0;
puts( s );
}
for ( i = 0; i < 128; i++ )
if ( curr->edge[i] != 0 ) {
s[x] = i;
find(curr->edge[i],x+1);
}
}
Comments
Post a Comment